


Deep neural networks can be trained to do the same thing, correctly identify a picture of a dog regardless of the color of its fur, or a word regardless of the speaker’s voice pitch. However, a new study by MIT neuroscientists reveals that these models often respond in the same way to images or words that bear no resemblance to the target.
MIT neuroscientists have discovered that computer models of hearing and vision can build their own idiosyncratic “invariants” — meaning they respond the same way to stimuli with very different features.
Human sensory systems are very good at recognizing objects we see or words we hear, even if the object is upside down or the word is spoken by a voice we’ve never heard.
Reactions of neural networks
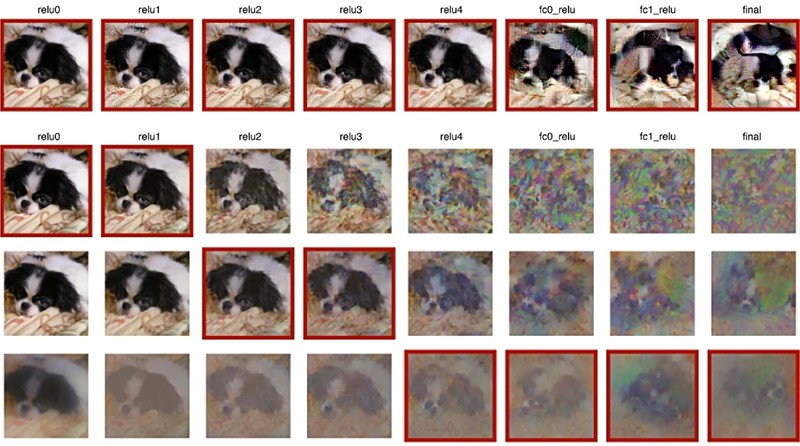
When these neural networks were used to generate images or words that responded in the same way as certain natural input, such as a picture of a bear, most of them generated images or sounds unrecognizable to human observers. This suggests that these models build their own specific “invariants,” meaning that they respond in the same way to stimuli with very different features.

The findings, reported in the journal Nature Neuroscience, offer researchers a new way to assess how well these models mimic the organization of human sensory perception, says Josh McDermott, an associate professor of brain and cognitive sciences at MIT and a member of the McGovern Institute for Brain Research and the Brain Center. minds and machines (CBMM).
Ignoring features
In recent years, researchers have trained deep neural networks that can analyze millions of input data, sounds or images, and learn common features that allow them to classify a target word or object about as accurately as humans do. These models are currently considered leading models of biological sensory systems.
It is believed that the human sensory system learns to ignore features that are not relevant to the fundamental identity of an object, such as the amount of light shining on it or the angle from which it is viewed. This is known as invariance, which means that objects are perceived as the same even if they show differences in these less important features.
Concept of metamer
The researchers wondered whether deep neural networks trained to perform classification tasks could develop similar invariances, so they can use these models to generate stimuli that produced the same type of response within the model. They call these stimuli the “metamer model”; the concept was originally developed to study human perception to describe colors that appear identical even though they are composed of different wavelengths of light.

Most of the images and sounds produced this way look and sound nothing like the examples the models were originally given. Those images are just a bunch of random pixels, and the sounds are unintelligible noise.
“People can’t actually recognize them at all. They don’t look or sound natural and have no interpretable characteristics that a person could use to classify objects or words,” the researchers explain. The findings suggest that the models have somehow developed their own invariances that differ from those of human perceptual systems.